AI คือ Auto Suggestion Text ใน Keyboard?
รู้หรือไม่ว่าจริงๆ AI มันมีมานานแล้วนะ เวลาที่เราพิมพ์แล้ว Keyboard ในโทรศัพท์จะขึ้น Suggestions นั่นคือ AI
ก่อนจะไปดูว่า AI มันเดาคำอย่างไร ผมจะพามารู้จักคำบางคำก่อน คำนั่นคือคำว่า Model
Model หรือ ภาษาไทยเรียก “แบบจำลอง” คือสิ่งที่เราสร้างขึ้นเพื่อใช้ “จำลอง” แทนระบบจริง ตัวอย่างเช่น
- Model พยากรณ์อากาศ → จำลองสภาพบรรยากาศเพื่อทำนายฝน
- Model ทางเศรษฐศาสตร์ → จำลองกลไกตลาดเพื่อทำนายราคา
ในทำนองเดียวกัน ถ้าเราเปลี่ยนจากการจำลองสภาพอากาศ มาเป็นการ จำลองวิธีการสื่อสารของเรา เพื่อให้คอมพิวเตอร์เข้าใจ เราเรียกสิ่งนี้ว่า Language Models (LMs)
Language Models (LMs)
ลองพิมพ์คำว่า “นาย” จะเห็น Keyboard แนะนำคำถัดไป นั่นคือแนวคิดพื้นฐานของ Language Model
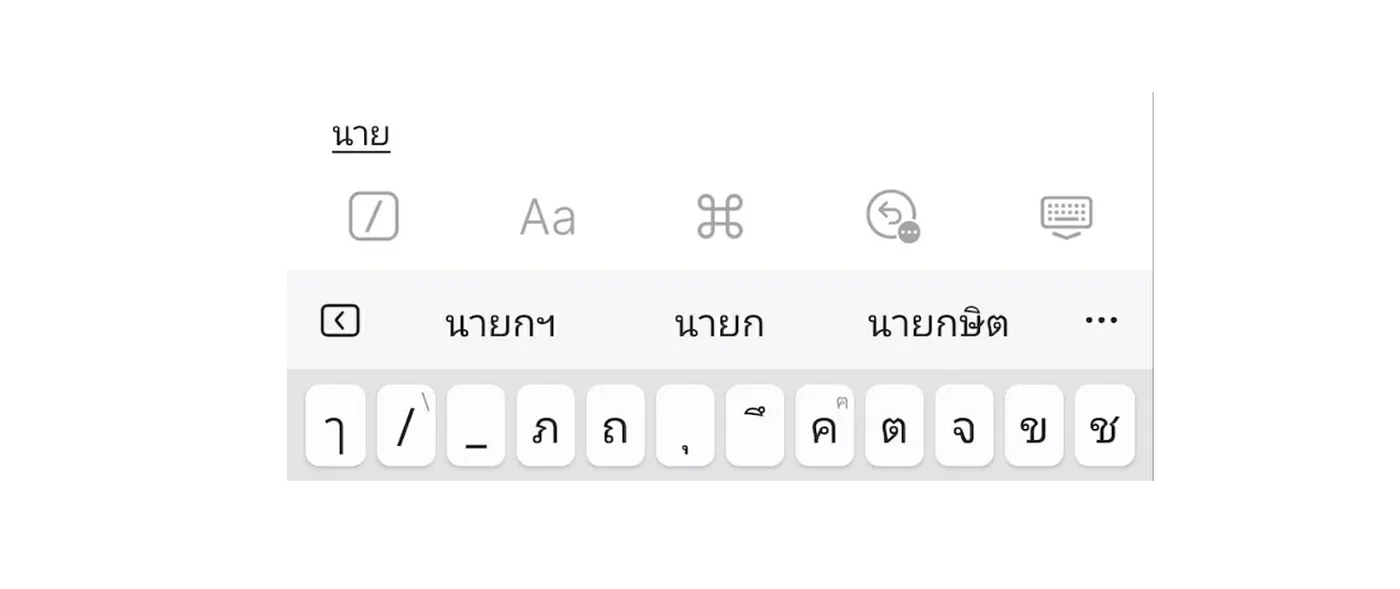
หน้าที่ของมันคือเมื่อได้รับข้อความที่เราพิมพ์ มันจะพยายาม “เดา” ข้อความส่วนที่เหลือให้จบ คำถามคือมันรู้ได้ไงว่าต้องเดาคำว่าอะไร?
ขอเล่าในย้อนไปช่วงปี 2010 เป็นต้นมาก็แล้วกัน เพราะถ้าเล่าจริงๆ ต้องย้อนกลับไปถึง 1990s ใครสนใจลองไปหาอ่านตามรูปด้านล่างเองนะ
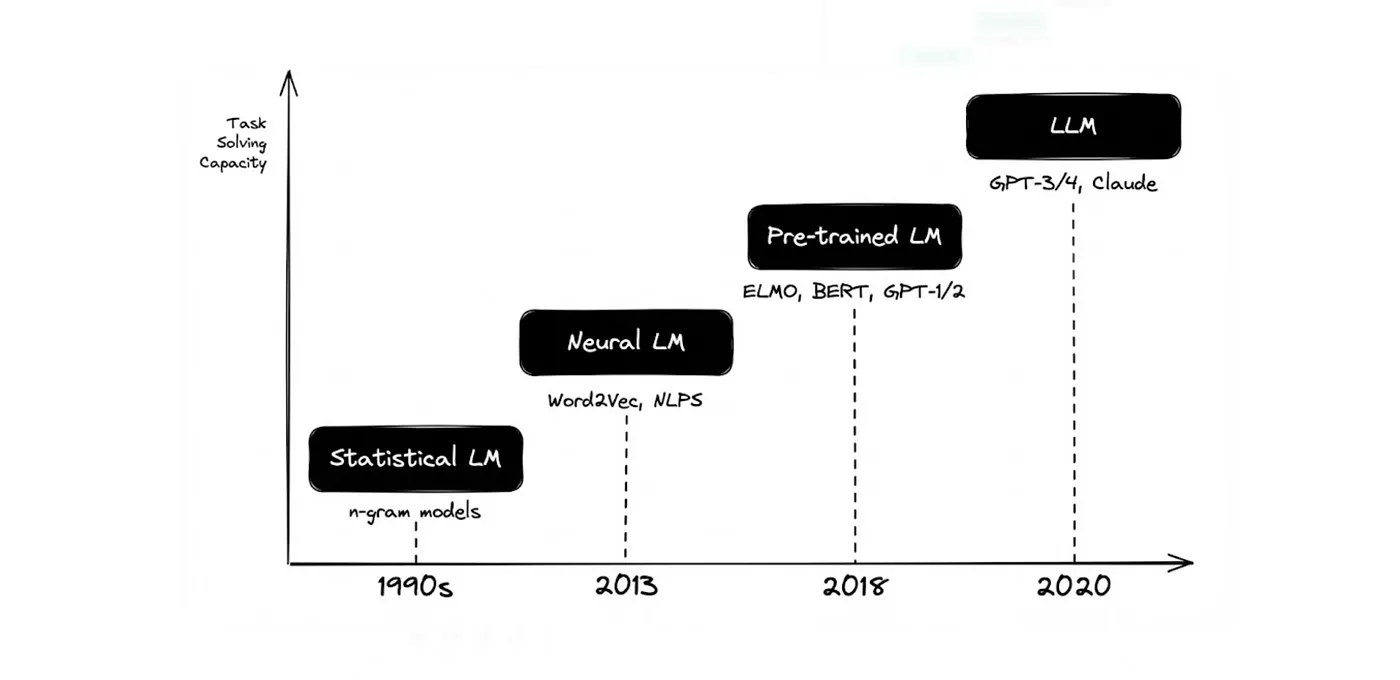
จริงๆ แล้วเป็นการใช้เทคนิคทางสถิติและความน่าจะเป็น เพื่อเดาประโยคถัดไป ในช่วงปีนั้นวิธีการ Training ตัว Model ใช้วิธีที่เรียกว่า Supervision
Supervision คือการที่มีคนมานั่งแปะป้ายกำกับ คอยป้อนโจทย์พร้อมเฉลยให้ Model บอกมันว่านี่คือ “คำที่ถูกต้อง” นี่คือ “คำที่ผิด” โดยข้อมูลแต่ละชุดจะประกอบด้วย:
- Input (โจทย์)
- Label (ป้ายกำกับ/เฉลย): ผลลัพธ์ที่ถูกต้องที่เราต้องการ
ตัวอย่างของ คำว่า “นาย” เราจะสอนให้ Model เดาว่า “คำถัดไปคืออะไร” รูปแบบ Dataset จะเป็นประมาณนี้:
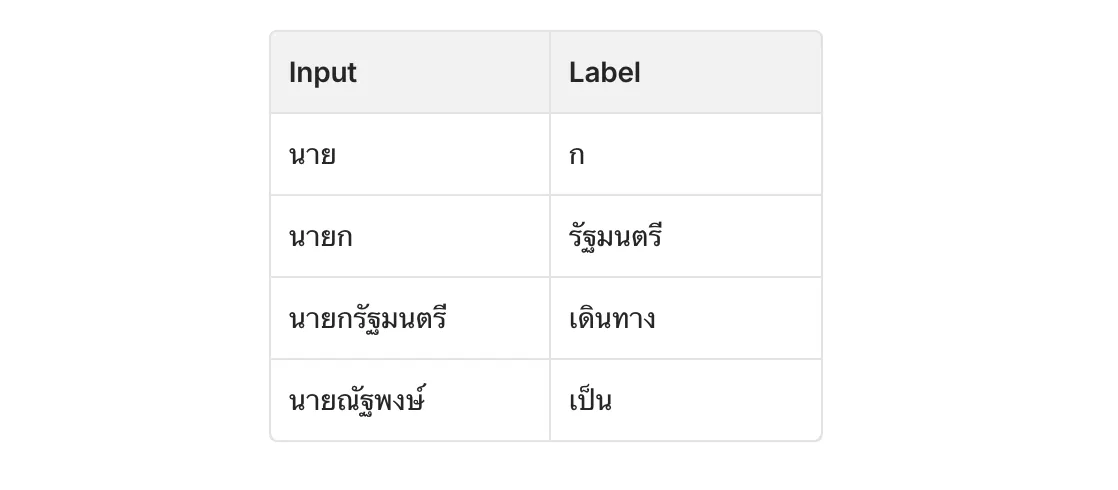
เวลาเราพิมพ์คุยกับเพื่อน จะพิมพ์เป็นคำ เป็นประโยคหรือส่งสัญลักษณ์ต่าง ๆ รูปหน้าตาแปลก ๆ ตาม Generation ที่เข้าใจกัน เราเรียกสิ่งนี้ว่า ภาษา แต่ใน Model การประมวลผล สิ่งนี้ไม่ใช่ “คำ” (Word) หรือ “ตัวอักษร” (Character) เราเรียกว่า มัน Token
Token
Token เป็นไปได้ทั้งตัวอักษรหนึ่งตัว, คำหนึ่งคำ, หรือส่วนหนึ่งของคำ
ตัวอย่างเช่น: GPT-5 (สมมติ) ถ้าพิมพ์ประโยคว่า: “Thailand election: The result the polls never saw coming”

จะใช้ทั้งหมด 10 Token แต่ถ้าเราพิมพ์ภาษาไทย จะใช้ทั้งหมด 18 Token

นี่เป็นที่มาของโพสใน Social ที่บอกว่าให้ Prompt เป็นภาษาอังกฤษ จะประหยัด Token กว่า เหตุผลเพราะว่าจำนวนการใช้ Token จะขึ้นอยู่กับโครงสร้างของภาษาและการออกแบบของแต่ละ Model
ความเห็นส่วนตัว: ผมเน้นผลลัพธ์ที่ได้มากกว่าจำนวน Token ที่ใช้ไป แต่ต้องดูที่บริบทและงานอีกทีด้วย
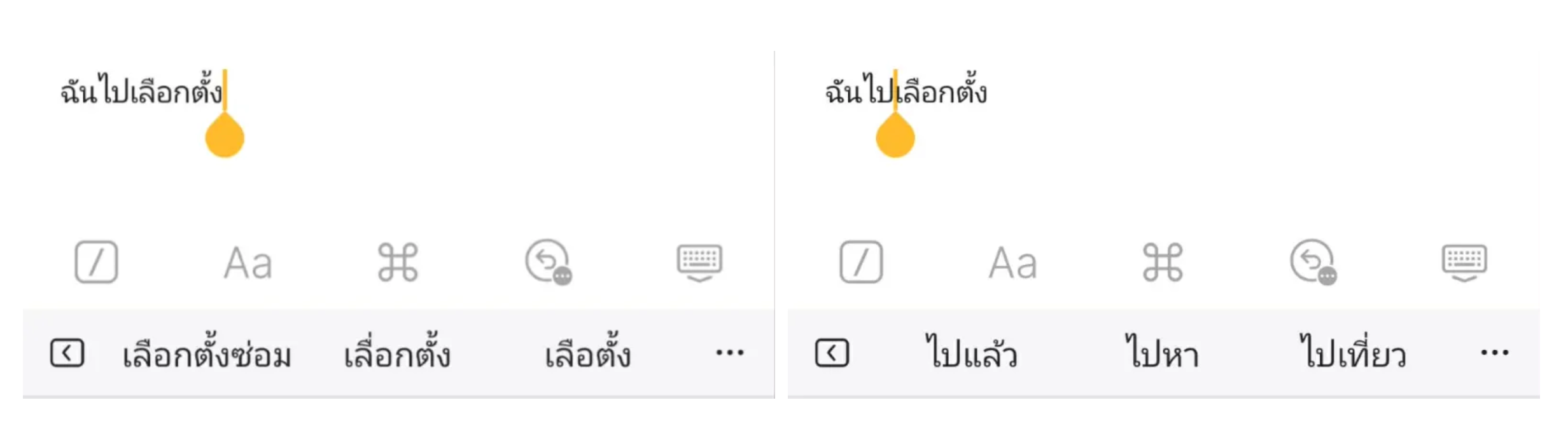
ย้อนกลับมาที่ Keyboard บนมือถือของเรา ให้ลองพิมพ์ประโยคยาวขึ้นพร้อมกับขยับ Cursor ไปมาระหว่างคำ จะสังเกตเห็นว่าการเดาคำถัดไปจะเปลี่ยนไป มาดูกันว่า Model มันคิดอย่างไร
Types of Language Models
Language Models แบ่งออกเป็นสองประเภทหลักๆ คือ Masked language models และ Autoregressive language models
Masked Language Models คือ Model ที่ถูกฝึกมาให้ ทายคำที่หายไป (Predict missing tokens) ในประโยค จุดเด่นคือมันสามารถดูบริบทจากทั้งคำข้างหน้าและคำข้างหลัง มาช่วยวิเคราะห์ว่าคำที่หายไปนั้นควรจะเป็นคำว่าอะไร
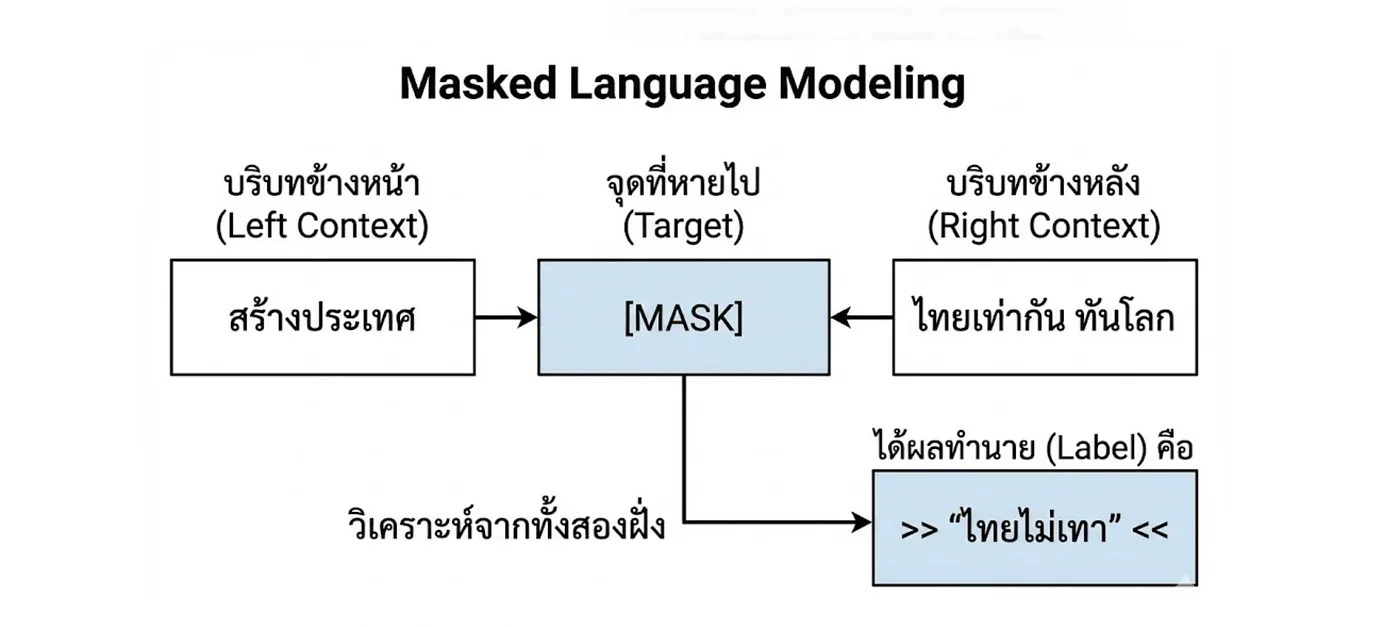
มันเดาคำในช่องว่างที่มีขอบเขตชัดเจน ผลลัพธ์มักจะเป็นคำที่ “ถูกต้องที่สุด” เราเรียกลุ่มนี้ว่า NLU (Natural Language Understanding) นิยมนำมาใช้กับงาน
- Sentiment Analysis: การแยกแยะอารมณ์ของข้อความ
- Text Classification: การจัดหมวดหมู่เนื้อหาให้ถูกต้อง
- Code Debugging: ช่วยไล่อ่าน Code ทั้งบรรทัดก่อนหน้าและถัดไป เพื่อเดา Code ที่ควรจะเป็นมาให้เรา จนบางทีต้องร้อง “ว๊าวซ่า!” ว่ามันรู้ใจเราได้ยังไง
Autoregressive Language Models คือ Model ที่ถูกออกแบบมาเพื่อ เดาโทเค็นถัดไป (Predict the Next Token)
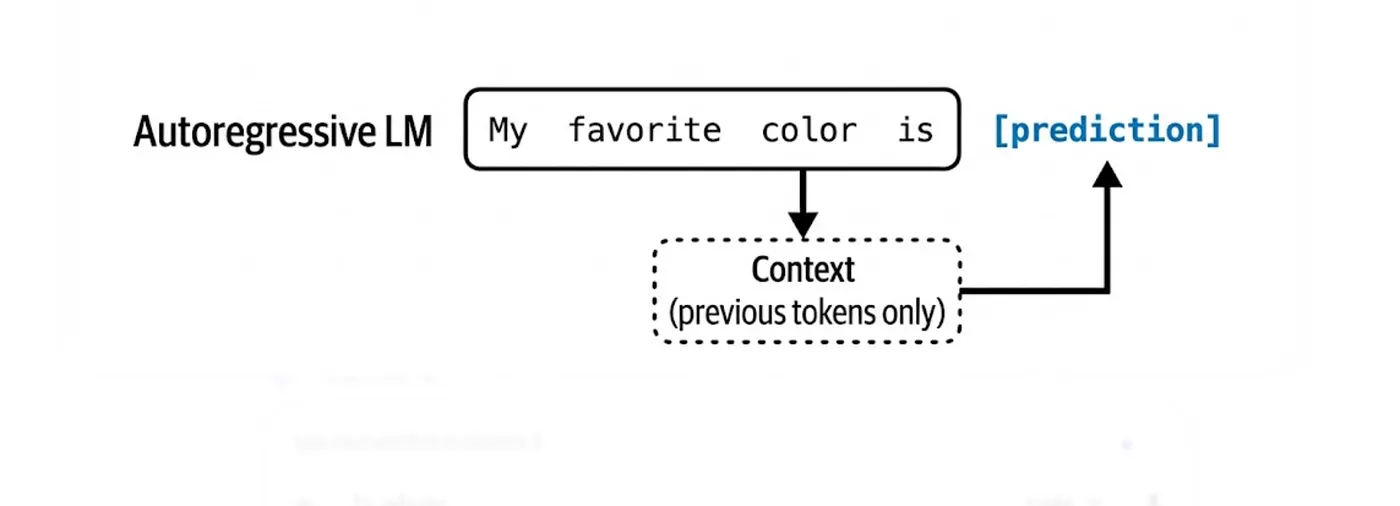
ตัวอย่างเช่น ในประโยค _“_My favorite color is __” Model จะเห็นแค่ “My favorite color is” แล้วเดาคำต่อไปคือ “orange” หรือ “orange” ถ้าเขียนเป็นลำดับจะเป็นแบบนี้:
- Input: A -> Predict: B
- Input: A B -> Predict: C
- Input: A B C -Predict: D
เมื่อเราโยน Prompt ให้มัน Model มันจะพยายาม “เดา” ข้อความที่เหลือให้จบสมบูรณ์ที่สุด ตัวอย่างเช่น
- Prompt (จากเรา): “To be or not to be”
- Completion (จาก AI): ”, that is the question.”
สิ่งสำคัญคือ ต้องรู้ว่ามันคือ การเดา(Prediction) บนพื้นฐาน ความน่าจะเป็น(Probability) ล้วน ๆ มันไม่มีอะไรรับประกันเลยว่าสิ่งนี้ถูกต้อง 100% ถ้าคุยกับ AI แล้วบางครั้งหงุดหงิดหรือบางครั้งแอบอมยิ้ม พฤติกรรมนั่นมันถูกต้องแล้ว By Design
Autoregressive language models คือสร้าง Generation ผลลัพธ์ที่เป็นไปได้อย่างไม่มีที่สิ้นสุด แบบจำลองที่สามารถสร้าง Output แบบปลายเปิดได้ เราเรียกว่า Generative เลยเป็นที่มาของคำว่า Generative AI นั่นเอง
From Language Models to Large Language Models
ก่อนหน้าเราพูดถึงวิธี Training เป็นแบบ Supervision ที่ต้องใช้คนมาทำ Labeled Data ข้อจำกัดคือ การจ้างคนมาแปะป้ายข้อมูลนั้นช้าและแพงมาก
ตัวอย่างเช่น: ถ้าค่าจ้างแปะป้ายรูปภาพอยู่ที่ 5 บาทต่อรูป การทำชุดข้อมูล ImageNet (1 ล้านรูป) จะต้องใช้เงินถึง 5,000,000 ล้านบาท ทางออกของปัญหานี้คือ Self-supervision
Self-supervision เปลี่ยนกระบวนการเรียนรู้ แทนที่จะต้องมีคนมาบอกว่า “นี่คือรูปแมว” หรือ “คำตอบคืออะไร” เป็นให้ Model กำหนด Labels จากของข้อมูลที่มีอยู่ โดยที่ Model จะเอาประโยคสั้น ๆ นี้มาร่วมเป็นคู่ฝึกฝนคือ
- “โจทย์” (Input context)
- “เฉลย” (Output label)
ตัวอย่างเช่น คำว่า “I love street food.” Model สามารถแตกออกมาเป็นคู่ฝึกฝน (Training Samples) ได้ถึง 6 คู่โดยอัตโนมัติ:

Self-supervised Learning ยังคงมีการใช้ Labels อยู่ โดยสร้างขึ้นมาจาก Raw Data ไม่ได้ใช้คนมานั่งติด ด้วยวิธีการนี้ ทำให้ข้อความที่อยู่บนโลกอินเทอร์เน็ต ไม่ว่าจะเป็นหนังสือ บทความ หรือคอมเมนต์ สามารถถูกแปลงเป็นข้อมูลฝึกฝน AI ได้ทันทีทำให้เราสามารถขยายขนาดชุดข้อมูลได้มหาศาล จนเกิดเป็นสิ่งที่เรียกว่า Large Language Models (LLMs)
คำว่า Large ใน LLM เดิมทีสะท้อนถึงขนาดของ Parameters ที่เพิ่มขึ้นอย่างก้าวกระโดด แต่ในปัจจุบัน “Large” หมายถึง Scale ของทั้งระบบ, จำนวนพารามิเตอร์, ขนาดของข้อมูล และพลังงานที่ใช้ในการประมวลผล
Conclusion
สุดท้ายแล้ว AI ก็คือ Auto suggestion ดีๆ นี่เอง แค่มันเก่งขึ้นเพราะได้รับข้อมูลการเทรนในปริมาณมหาศาล จนดูเหมือนว่ามันกำลัง “คิด” ทั้งที่จริงๆ แล้วมันแค่ “กำลังเดาคำถัดไป” อยู่ตลอดเวลาเท่านั่นเอง
ผม GLM ของทาง Z.ai ใครอยากสนับสนุนผมสามารถ สมัครผ่าน Invitation Link: https://z.ai/subscribe?ic=RCPQTOLJD5 ได้เลยครับ
บทความถัดไปจะเล่าเรื่อง From Large Language Models to Foundation Models ฝากติดตามด้วยนะครับ